Fastbook (FastAI) Chapter 1 Questionnaire
QnA
Q1. Do you need these for deep learning?
- Lots of math T / F
- Lots of data T / F
- Lots of expensive computers T / F
- A PhD T / F
A. In general, No. However, it does depend on how much depth you are wanting to explore.
Lots of math? Not an entry point to do deep learning. However, after a certain stage, you might want to know what is actually making it work. One might not want to do anything with the internals of a working system until the internals start giving problems that are difficult to manage. For example, when something goes wrong with the television, one might want to open it up to see whats wrong or simply outsource to get it fixed. It depends on the level of curiosity a person has and what the she wants to achieve.
Lots of data? Again depends on the task at hand. In general, though, a deep learning model can be trained on a CPU to perform pretty good. If one is expecting to beat the benchmarks, the model for which has been trained on large amounts of data, then it’s imperative (mostly) to presume one might require large amounts of data. With that being said, pre-trained models for most of the tasks are available and this reduces the data required to train the models.
Lots of expensive computers? Once again, depends on what the task is. A person wanting to learning deep learning would absolutely not require expensive computer power on in fact any of the above things either. If solving a problem facing the company one is working with, the compute might be easily accessible using a lot of cloud providers and be really cheap.
A PhD? It is similar to the answer to the question about lots of math. The distinction lies in acknowledging that even without a PhD, a person can learn the Math if interested. A PhD is possibly an easy way in that you have a mentor assisting you.
Q2. Name five areas where deep learning is now the best in the world.
A. Computer Vision(Object classification, detection, segmentation), Natural Language Processing (Sentiment classification, Machine translation), Recommender systems, Playing board games (Atari, alpha-go, chess), Generating approximate models for prediction in Physics which might otherwise take lots of math computations.
Q3. What was the name of the first device that was based on the principle of the artificial neuron?
A. Mark I Perceptron
Q4. Based on the book of the same name, what are the requirements for parallel distributed processing (PDP)?
A.
- a set of processing units:
- a state of activation
- an output function for each unit
- a pattern of connectivity among units
- a propagation rule for propagating activities through the network
- an activation rule for combining inputs to unit with current state of unit to produce output for the unit
- a learning rule using which patterns of connectivity are modified by experience
- an environment within which a system must operate
Q5. What were the two theoretical misunderstandings that held back the field of neural networks?
A.
- A single layer network is not able to approximate even the simplest of mathematical functions.
- Adding a more layers is not feasible practically. The networks would be too big and slow to be useful.
Q6. What is a GPU?
A.
A special kind of hardware that allows multiple operations at the same time. So, in a CPU, let’s say we have 8 cores. That means, only 8 processes can run in parallel in actuality. Let’s not confuse multi-processing with multi-threading. So, a GPU has lots of cores which helps Deep Learning models perform lots of calculations at the same time and hence makes the models run faster. There are other differences like the CPU being more smarter and capable of handling different types of tasks but limited by total number of tasks it can do at a time. The GPU on the other hand is good on particular/limited set of tasks that are related to calculations, image/video rendering and many of those at the same time.
Q7. Why is it hard to use a traditional computer program to recognize images in a photo?
A.
Short answer
Due to the complexity involved in finding heuristics to match the patterns. There are too many patterns to be hard coded.
Long answer
Digitised images are represented as pixels and each pixel in an image has some value. Let’s take an example of a 10x10 image that has a dog. There are a total of 100 pixels in the image. If we are to predict whether the image is of a dog or not, we might have to have heuristics about all the 100 pixels and the values for the dog. Now, some images might have been taken on a rainy day, so the pixel values might change for the same dog. So, our task would be to find if the image has a rainy aspect, de-noise it and then do what we did earlier. To add complexity let’s say the first image had dog to the left of the frame whereas the newer one has it to the right, now this completely changes the pixel values. There are the complexities for a single dog breed or possible a single dog, with a fixed image size. Imagine having to classify 100s of dog breeds, each having different image sizes, and other factors like objects, seasons, etc. Now, to up the ante, let’s say we want to classify 100 different animals, or any object on earth. The complexity is too much for a traditional computer program to solve. We need a learning architecture that can do this without we explicitly saying anything other than showing some examples of the label and asking the architecture to predict when shown a new image.
Q8. What did Samuel mean by “weight assignment”?
A. Weights are the parameters we learn to improve the performance of our model. In general, weights can be seen as one of entities other than the inputs (data) that influence the result i.e. whether an image is of a dog or not. We perform some arithmetic operations by combining inputs with weights to get predictions.
Q9. What term do we normally use in deep learning for what Samuel called “weights”?
A. Parameters. (Weights are a type of parameter)
Q10. Draw a picture that summarizes Samuel’s view of a machine learning model.
A.
Arthur Samuel’s words, “Suppose we arrange for some automatic means of testing the effectiveness of any current weight assignment in terms of actual performance and provide a mechanism for altering the weight assignment so as to maximize the performance.”
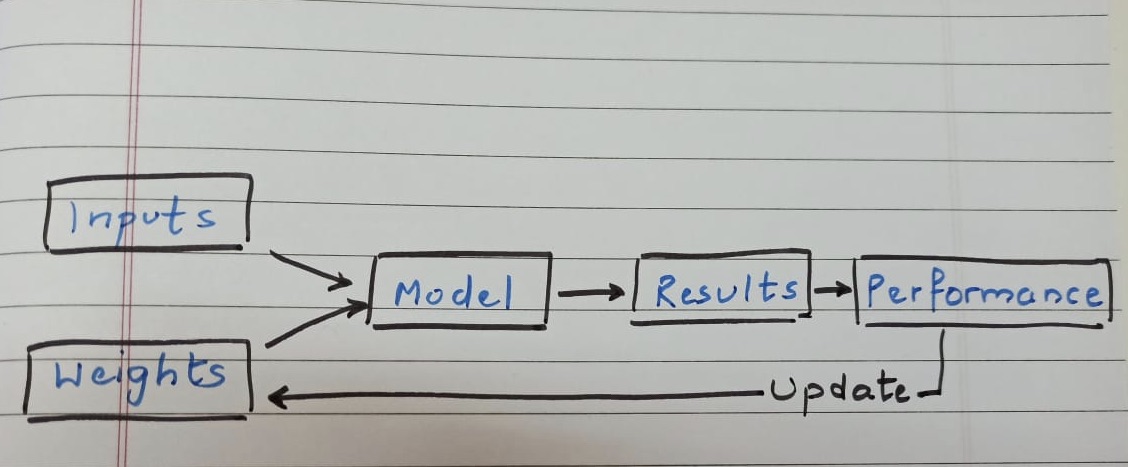
Q11. Why is it hard to understand why a deep learning model makes a particular prediction?
A. There are many layers and each layer has many neurons and activation functions and it feels like its difficult to understand so many details. There is still a level of understanding one can achieve using shallow networks but gets complicated when the number of layers and the neurons in each layer increase. To give a perspective, some of the models today have millions and billions of parameters and visualising the activations at each layer is quite difficult. However, there have been examples when visualising CNN’s layer by layer activations that have showed evidence of correct neurons firing leading to the final prediction. However, we have to acknowledge the fact that it is not as easy as in statistics or statistical models. Explainable AI is being highly researched nowadays and considered a very important problem to solve.
Q12. What is the name of the theorem that shows that a neural network can solve any mathematical problem to any level of accuracy?
A. Universal Function Approximation theorem (in theory)
Q13. What do you need in order to train a model?
A.
- Data and their corresponding Labels
- Once we have “#1”, we will have to choose the hyper-parameters and an architecture to train the model
Q14. How could a feedback loop impact the rollout of a predictive policing model?
A. The obvious one is improves the accuracy of the prediction. But, the major one is it reduces the bias.
Q15. Do we always have to use 224×224-pixel images with the cat recognition model?
A. No, it is mostly to ensure that the image is the same size as the images that were used to train a model and if we are using pre-trained weights. In general, we can use any size. However, one must be aware of the tradeoffs. A smaller image size would be faster to run, but might impact the performance because a lot of information might be lost due to compression. On the flip side, a larger size might give excellent performance but might take a lot of time and compute resources. The decision should be based on the needs of the person training the model.
Q16. What is the difference between classification and regression?
A.
Classfication : Labeling data into the categories. They are discrete in nature. For example, classify whether an image is a dog or cat (image), classify the sentiment of the given review (text), etc
Regression : Predicting numeric values. These are continuous in nature. For example, Regressing over stocks from the last 30 days to predict what will be its value tomorrow, based on the house features predicting what is it’s price, etc
Q17. What is a validation set? What is a test set? Why do we need them?
A.
Our main goal in a machine learning experiment is to be able to predict the outcome when given data. Now, let’s say we developed a model and want to demonstrate it to everyone (probably team) before deploying it. After careful consideration we have decide Accuracy as the metric to better gauge the members of the team and also make the inference simpler. So, let’s say we mention that the model has an accuracy of 90%. How did we calculate it?
Scenario 1:-
We had 100 data points which we trained the model on. Finally, we used the same images to see how well the model predicted the output and we declared that the accuracy is 90%. The problem with this approach is that in the real world, we might get data that did not belong to the data we trained the model on and hence might or might not work well.
Scenario 2:-
We understood that it is important to test the model on some data that model has never seen before and report the model’s accuracy on that data. We call this the test set. We go ahead and build the model and to our surprise, our accuracy has dropped to 60% and this is not acceptable. How would we know whether we overtrained or undertrained and how to improve the model?
Scenario 3:-
We create 3 sets out of the original data. So, for practical purposes, we use 70 data points for training, 15 for testing, and the remaining 15 for validation. Now, we use the train set to train the model. We keep checking the performance on the validation set and keep updating the model hyper-parameters and decide whether we are over training or under training the model. Finally, when we are satisfied with the results, we measure the performance i.e. the accuracy on the test set and report it.
Important Tip:
Based on the above case, we are actually a bit biased on the validation set, because we end up using the hyper parameter values that give max performance on the validation set but the images are not used for training. This is the reason we need the test set to report results and keep our ambitious over estimations in check.
Q18. What will fastai do if you don’t provide a validation set?
A. FasiAI assumes that we are either lazy or have forgotten that this split is necessary to learn better and not overfit; and hence automatically takes a percentage of data points as validation set.
Q19. Can we always use a random sample for a validation set? Why or why not?
A. It depends on the type of problem we are solving. If the problem is to classify images as dogs or cats, whether to classify a review as positive or negative, a random sampling will work just fine an in fact is highly recommended.
However, let’s say we want to predict the price of the stock where a certain value at a point in time will depend on the values before the and hence, it might not be wise to randomly sample. In such cases, assuming we have 100 data points ordered by time, we can choose the first 80-85 as train set and the remaining as the validation set.
Q20. What is overfitting? Provide an example.
A. If we are learning the training set, as a result of which the accuracy on the training set is good, however, works poorly on never seen data, then we can say that we are overfitting to the training set. For example, if we have 100 images of dog that we trained a model on to classify whether or not the image is of a dog. If the predictions work well on the dogs in the original training set (100 images) however, does poorly on never seen data, we can say that our model has overfit to the training set.
Q21. What is a metric? How does it differ from “loss”?
A. A metric is a unit that is helpful for humans to understand the model performance. A loss is a unit that is helpful for the model to understand the performance.
Example:
We can define ACCURACY as a metric to tell the stake holders how well the model is performing. We can use LogLoss as a loss to tell the model to update the weights based on how wrong its predictions are. To remember Arthur Samuel’s statement, loss is actually a way for the neural network to “measure performance”.
Q22. How can pre-trained models help?
A. As we know, neural networks have a layered architecture, meaning there are several layers and each learn a particular representation about the data we are working on. Now, we can say that classifying whether a dog or not is a subset of classifying several dog breeds which is a subset of classifying several animals and so on. Which means by having a model that classifies animals, we might have implicit information about dogs somewhere in the network, which we make use of to train a model to classify dogs.
So, instead of having to train all the layers from scratch (which takes a lot of compute and time), we use the layers that give basic understanding about the characteristics about animals, and probably tweak and retrain the final layers to make it work for dogs.
Q23. What is the “head” of a model?
A. The layers from the pre-trained model that have been retrained to map to our use-case. For example, we use the ImageNet pre-trained model which is trained on thousands of categories of images and fine tune some final layers (head) to make it work on our dogs dataset or any other image dataset for that matter which might have similar initial layers.
Q24. What kinds of features do the early layers of a CNN find? How about the later layers?
A. Let’s consider an example of dogs dataset. The early (left -> right) layers might learn edges. A bit further, the layers might learn lines, curves, etc. Further deep, layers might learn eyes, nose, neck, etc. Further deep, layers might learn if there are faces or not, if yes whether they are of people or animals, etc. Finally, the last few layers might learn to classify whether dogs or not. This is exactly why we use pre-trained models which have the learned representations in the initial layers that are common to most images that might be beneficial for most tasks. (Follow up answer to Q22)
Q25. Are image models only useful for photos?
A. Nope. Even, other types of data can be converted into images and we can use them for solving non-image data problems.
An example is detecting anomalies in time series data. As opposed to the general way of dealing with sequence data using LSTM’s or any other Sequence models that take into account the context of the data; one can draw line plots of the data, label the anomalous ones, and use a image model like CNN to find anomalies in test data. In fact, to add to this, one can even draw bounding boxes around anomalous area and train the model to detect these regions using an Object detection image model.
Q26. What is an “architecture”?
A. In the neural network terminology, an architecture is an arrangement of layers of neurons which are arithmetic units, stacked next to each other to propagate signals that will help accomplish our task of regression, classification, etc
Q27. What is segmentation?
A. Segmentation is extracting the entities of interest that form some meaningful groups. For example, from a set of customers, we segment customers based on their buying patterns. This helps us decide who to send advertising notifications to. Another example can be if checking a geographical terrain for some important piece of information, segmenting out the most important part of the figure and focusing on that because these images can be pixel dense. This makes it hard for a naked eye to find information easily.
Q28. What is y_range used for? When do we need it?
A. This is specific to FastAI API. If instead of categories of values we are predicting continuous numbers, we have to explicitly mention the range of the values of the predictions.
Q29. What are “hyper-parameters”?
A. Hyper-parameters are like knobs in machine learning used to train the models efficiently. These hyper-parameters may improve our model performance, reduce the time taken for the model to train, etc. Some examples are, number of layers in the network, the learning_rate, the total number of iterations to train the model to, etc. These are mostly learned by experimentation and there are no set rules in most of the cases.
Q30. What’s the best way to avoid failures when using AI in an organisation?
A. There are quite a few things that can go wrong.
- Jumping into modelling without understanding the data.
- Validating the data is representative of what is out there in the wild.
- Over training or under training without considering the domain we are working on.
- Not trying simpler models first before jumping into Deep Learning and other more complex models.
- Not experimenting enough either due to the fear of failure or giving up early.