Machine Learning to Production
Problem Statement
The Problem
Yarn capacity allocation needs to be accurately setup for stable workload processing. Yarn queues often run out of capacity and in turn stall critical workloads, queries and jobs. The objective was to forecast such resource Outages and prolonged under utilisation for various Queues in Hadoop clusters. YARN.
The Outcome - Enable Cluster Operators to plan capacity allocation
Such pre-emptive Forecasts, will help the Business Users to perform Capacity Planning to meet their SLAs, and reduce the number of failures that are caused because of lack of capacity in Yarn Queues.
To give you more information about this, the queues in YARN can are similar to queues in Data Structures and used for the task of scheduling (read more here) of jobs, tasks. So, these queues are given a certain capacity which can be imagined to be the number of tasks, jobs that can be stored in it. The queue can be partitioned into multiple sub-queues. The queue has a property which is its ‘Used Capacity’ at a point in time. Our task is to forecast how much capacity of the queue will be used at some point in the future.
But, the important point to note is that this is a Multi-variate forecasting problem. In short, the value of absMaxCapacity depends on the other features (numActiveApps, numPendingApps, etc) from a past time period.
Let’s talk a bit about the components that we will discuss throughout the post and how they are interlinked and complete the puzzle i.e. ML to production at Acceldata.
Solution
Let’s see step by step how we developed the infrastructure to tackle the problem of Prediction or Forecasting the Resource Usage.
Simple High Level (System) Design

Our production pipeline should read in data from DocumentDB, prepare the data for modelling, train and forecast the data, finally write back to TSDB. The Business Users read this data from TSDB using Acceldata Dashboard.
Let’s start going through each of the above components i.e. DocumentDB, the ML pipeline that crunches the data and finally the results written to TSDB.
DocumentDB
We use DocumentDB to store log information of all the components that we support (check here) and also resource usage values for each of the queues in YARN. Now, to analyse and write predictive algorithms about this data, it is imperative that we import this data and then process it.
Below is a snapshot of how the data looks like. This data is collected by our connectors for each of the components we support.
| _id | absMaxCapacity | numActiveApps | numPendingApps | vcoresTotal |
|---|---|---|---|---|
| 1 | 100 | 75 | 75 | 1071 |
| 2 | 15.34 | 1 | 1 | 164 |
| 3 | 28.57 | 31 | 31 | 306 |
| 4 | 38.09 | 41 | 41 | 408 |
| 5 | 18 | 2 | 2 | 193 |
Each of the rows above describe the status of a queue at a particular point in time. Our main focus would be to predict absMaxCapacity in the future.
ML Pipeline
- Clean and Preprocess the data and get it ready to pass to a time-series model.
- Train the model and based on error criteria (discussed below), choose the best model
- Forecast predictions, upper bound as well as lower bounds
- Prepare data to write into TSDB
A detailed explanation for each of the Machine Learning Steps involved is discussed later in this post.
Dashboard
Finally, time to see the results! A Data Science project is incomplete without visualisation. The predicted data that is pumped into TSDB is rendered to the UI and below is how the predictions look like.
The below images show 2 queues i.e. DEFAULT and LLAP which are sub-queues under root queue. The first image merges the actual queue usage and predicted queue usage for the current day. The second image is the predictions for the next day. The number of days to predict in the future is a configurable param that is present in the Data Model section.
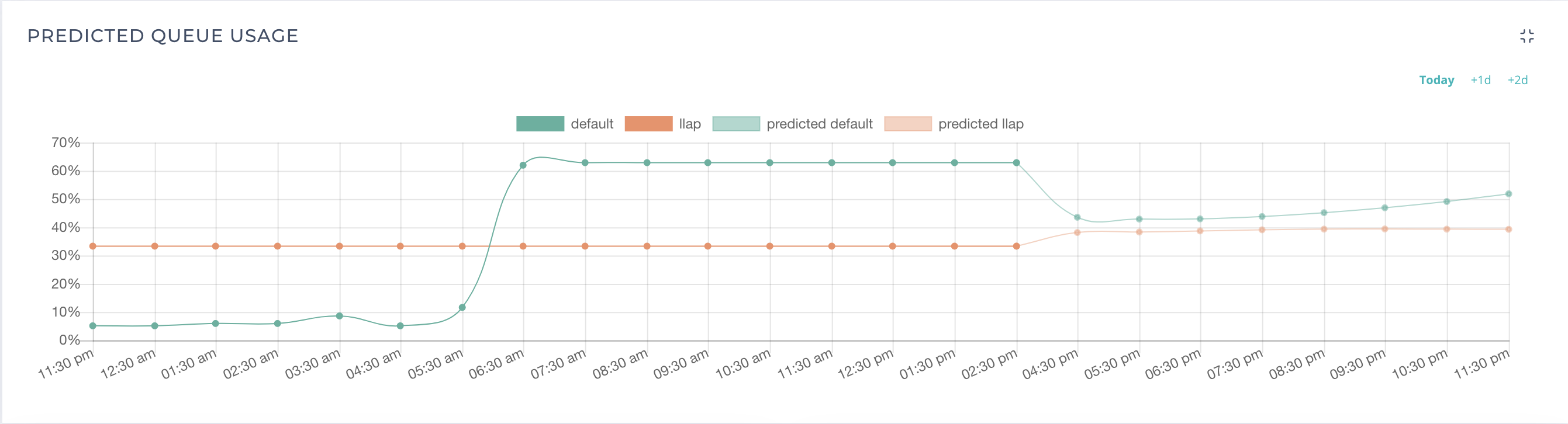
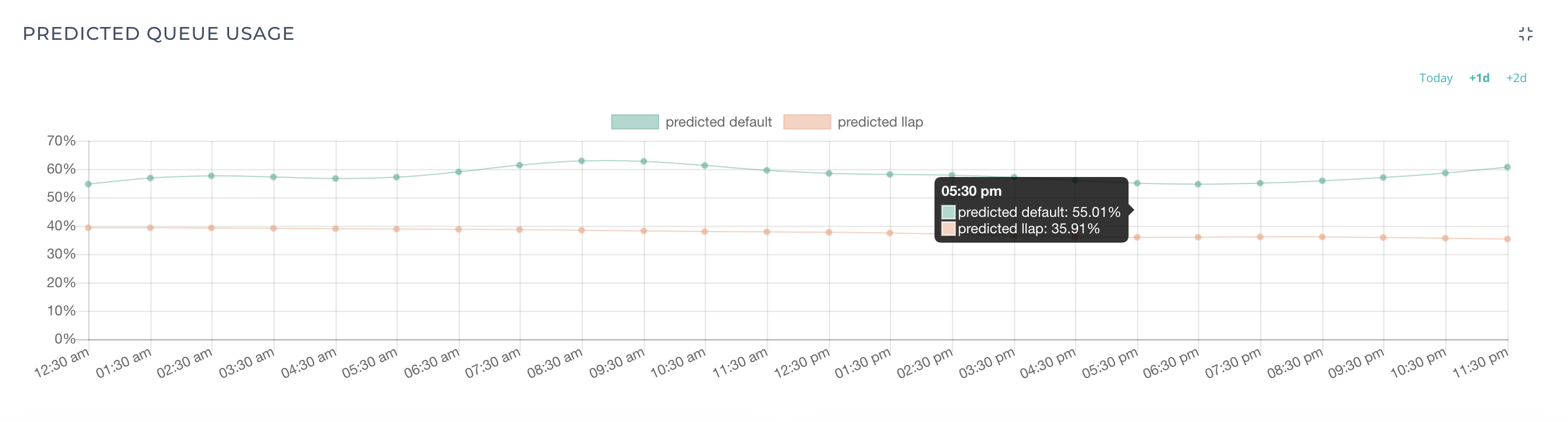
Looking at the Machine Learning Pipeline in detail
This is the most important section and actually explains what the title promised. Let’s discuss what all are the parts when stitched together help us get a Machine Learning model to production.
Software Engineering
Below are some of the tasks that fall under the software engineering category and important to complete the pipeline.
- Designing Database Access Layers also called DAO
Since we are dealing with multiple sources of data, we cannot expect the business user to specify how to query the sources for data. We expect them to specify where the data is located. Writing code to extract data from different sources lies in the hands of the Software Engineers that design the these systems - Web App layer to get details about the params for the Data Ingestion sources
The business users request data through this layer that stands as an interface between the Machine Learning models and them. For this to happen, a usual practice is to design an API or Data Model that can be exposed via a REST/web layer discussed in the above point. We will look at it separately in the Data Model section - Dockerization/Containerization
Our ML models run in separate docker containers and hence can be integrated with any of the other services that we develop. The initial setup took some effort but the development times kept on reducing as we started dockerizing other ML based apps as well
Data Engineering
There are blog posts that discuss how Data Engineers extracted data from different data sources and warehouses, and merged them and pushed to a SQL or NOSQL db or even CSV files so that the Data Scientists would be able to work seamlessly with the data. I will simplify it and discuss how I performed data engineering to get data into the Machine Learning models.
- In most cases where devs are dealing with multiple data sources and various business users, the data engineering pipelines get complicated. Data storage and retrieval becomes a huge headache and choices of SQL vs NOSQL vs warehouses, Batch vs Stream processing, etc kick in design discussions about such cases are topics for another post.
- For us, the data sources are TSDB and DocumentDB store. Using the abstracted tools from the Software Engineering section, we can get this data in the format that is desired using various db clients. Most of the code for this is written in Python and most of API clients have a provision to get this data in the DataFrame format that is best suited for Machine Learning models.
Now that we have our data extracted and ready for Machine Learning model, let’s head into seeing what are the various parts in Machine Learning.
Machine Learning
Import Data
Once the data engineering (simply data ingestion) module is ready, data is imported, merged and mutated into a DataFrame which is easier to work with Data Science workflows. The ML module now has the queue data in DataFrames format.
Below is an example of how a Data Importer module looks.
Clean Data and Feature Engineering
As you might have heard more than a thousand times and almost every one discusses this as the most important aspect of Data Science, the current workflow also uses this aspect very well. Some of the techniques used are:
- Cleaning Unwanted Columns
- highly correlated data (noisy data)
- extra columns that may be passed by the data source
- Developing Useful Time Features
- day of the week/hour/month
- week of the month/year
- month/quarter of the year
- holiday
- whether weekend or not
- proximity to weekend
- Normalising/Scaling Data
I have seen this data preparation technique improve results almost all the times. It is just easy for the model to comprehend data that fit in the same scale. - Sample Data
The data captured from Hadoop and other components and system metrics is too frequent (seconds) to be used directly for modelling and hence sampling into higher time measures is very important using aggregations like mean, median, min, max depending on the use-case. This way a lot of noise is excluded from entering the model.
Fit Data and Forecast
- Now that we have the data ready to be run model on, we choose the train and test data and use multiple algorithms to see which one of the Algorithms, hyper-params and params give best results.
- The best model is chosen and forecasts are then generated. Our models are an ensemble based on Facebook’s Prophet, LSTM and VAR.
Below is an example of how the Forecast Module along with Data Preparation code looks.
Evaluation of the Models
Evaluation or Error Calculation is the measure that decides which model works better and should be chosen for forecasts on production data. Since dealing with absolute values, to avoiding overcomplicating stuff, we use MAPE as the error measure.
Prepare Data for writing results to DB
Data preparation is not only necessary to train the model. When we often write back data to some database, some design choices have to be made so that the end/business users can make appropriate use of the data. Tasks can be something like:
- adding time as a field or even making it a primary key
- writing data keeping in mind the indexes for the tables/documents/measurements
- adding extra incremental fields in very rare cases that might be required by the charting libraries to render and display on the
Below is an example of how the Data Writer looks.
TSDB
Now Most of the data that we collect at Acceldata is time-series based and it only makes sense to store it in a Time-Series database. Since the predictions are time-series based i.e. the forecasts are timestamps in the future displaying the queue usage, all the predictions are written to TSDB. We acknowledge the fact that no one can be perfect. So along with the predictions, we make sure to predict the upper and lower bounds of the queue usage so as to give the business user a perspective of how much variance one can expect.
This is how the data in TSDB would look like:
| time | prediction | upper_bound | lower_bound |
|---|---|---|---|
| 1563532623 | 70 | 90 | 63 |
| 1563532633 | 30 | 42 | 12 |
| 1563532643 | 15.5 | 22.4 | 8.5 |
| 1563532653 | 78.8 | 90.5 | 70 |
| 1563532663 | 89 | 100 | 82.1 |
How to interpret the above results?
We can say that, for the 1st and 4th timestamps, the queues seem to have been running on full capacity, however, in the 5th timestamp, the queue might see an overflow condition as the upper_bound value suggests. So, in cases where such pattern seems to be for a long period of time, the cluster might not perform well and hence Business Users (SRE’s) might want to upscale the cluster.
Another important finding can be that during the 2nd and 3rd timestamps, the queues might go under utilised. In this case, the Business Users might prefer downscaling to pull the TCO down.
Data Model
This is where software engineering again comes into picture. The business users have better idea about the sampling, frequency and prediction periods (remember we mentioned earlier accepting information from business users). So, it makes sense to accept these kind of params from the users and prepare our data or run our models based on them. This can be highly debated but suited our use case. Below is a sample of the request payload.
{
"job_name":"queue_usage_forecaster",
"job_description":"Get predictions for next 'k' days/hours/months",
"user_name":"Bob",
"project":"Capacity Forecasting",
"owner":"ui-service",
"data":{
"source":{
"name":"documentdb",
"document":"<replace_with_apt_name>",
"collection":"<replace_with_apt_name>"
},
"destination":{
"name":"tsdb",
"database":"<replace_with_apt_name>",
"measurement":"<replace_with_apt_name>"
}
},
"aggregation_time_period":"1h",
"data_ingestion_time_period":"5d",
"future_prediction_time_period":"3d"
}
This can be persisted in a db to keep an account of the usage but again for brevity I will skip discussing about it.
Conclusion
We have seen how we can use Machine Learning to predict BigData workloads that helps business users take accurate actions. In one of the following posts, we will discuss auto-action feature that is in Beta that will remove a huge workload from the Business users as well where our platform takes the recommended actions in case there is any foreseen problem. Along with that, we also have a good idea of how to productionize ML pipelines and how Software Engineering, Data Engineering and Machine Learning all play a role in the Productionization of such pipelines.